944 Delete Columns to Make Sorted
A list of strings is a 2-dimensional array by definition. The solution to this problem is fairly simple at a glance: We just need to look at each column one by one, and count the number of columns that are not in increasing order from top to bottom.
Thus, my first attempt was as follows:
class Solution:
def minDeletionSize(self, A: List[str]) -> int:
counter = 0
for i in range(len(A[0])):
if not all([A[j][i] <= A[j + 1][i] for j in range(len(A) - 1)]):
counter += 1
return counter
This seems good enough, right? Apparently not; My best run-time was 204ms, beating only 31.09 of all python3 submissions.
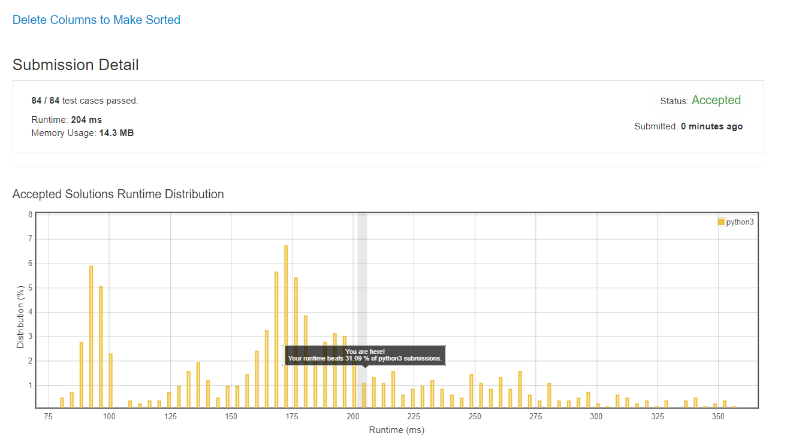
So what gives? Why isn’t my solution good enough?
It turns out we can further optimize this solution by utilizing an iterator.
For this purpose we’ll use python’s handy method “zip”. (For more information about zip see ) Zip returns an iterator of tuples, where the i-th tuple contains the i-th element from each of the lists in A.
We see an immediate improvement when we change the outer loop to use an iterator instead.
class Solution:
def minDeletionSize(self, A: List[str]) -> int:
counter = 0
for col in zip(*A):
if any([col[i] > col[i + 1] for i in range(len(col) - 1)]):
counter += 1
return counter
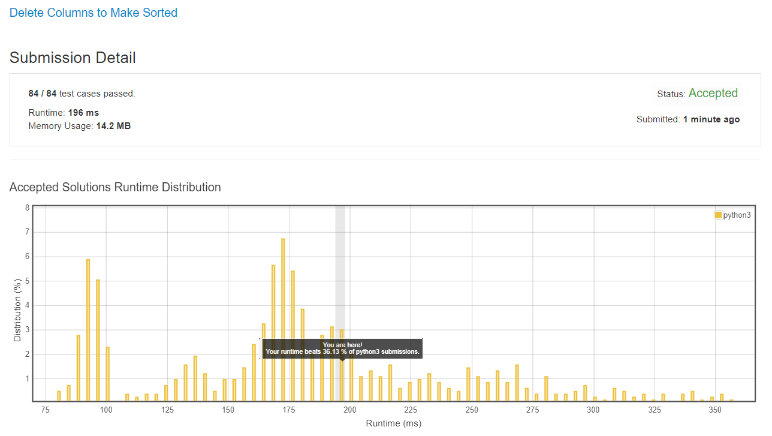
A 5% improvement! Not great… but an improvement nonetheless. So let’s further optimize this by applying this idea to the inner loop:
class Solution:
def minDeletionSize(self, A: List[str]) -> int:
counter = 0
for col in zip(*A):
if any([a > b for a, b in zip(col, col[1:])]):
counter += 1
return counter
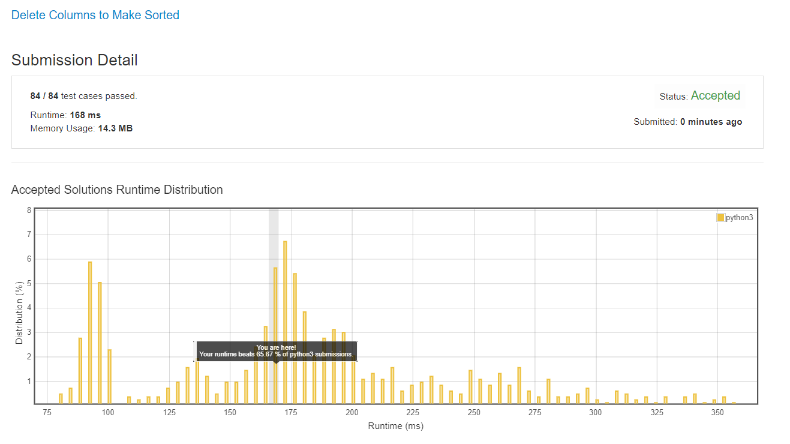
Almost 100% improvement! Wow, incredible!
So why is an iterator so much faster then a simple loop? This is largely due to how list are stored in memory vs how iterators get stored in memory.
In, particular when a list is large enough, your local cache may not be large enough to contain the entire list, in which case your memory will be utilized.
This will ultimately affect your performance due to slow memory access times relative to the speed of your processor. On the other hand, iterators re-use the same
memory location on each iteration. Credit to Raymond Hettinger for this insightful answer:
Iterators have a tiny constant size while lists take space proportional to the length of the list. The part that is not obvious is that looping over the iterator re-uses the same memory location again an again. So the relevant data is almost always in the hardware memory cache. The same is also true for small lists. However, large lists cannot all fit in the cache and accessing them will be slower than their iterator based counterparts. As processor speeds race ahead of memory speeds, the performance difference will become more pronounced over time.
Furthermore, there is a cost involved in allocating Python objects. But, smart allocators save time when it can reuse recently discarded objects. This works well for iterators, which continuously reuse the same memory. Once again credit to Raymond Hettinger for this insightful answer:
It takes time to allocate Python objects, but the smart allocator saves some of that time when it can reuse recently discarded objects. This technique works very well with iterators which tend to continuously create and abandon many same sized objects. However, list based approaches keep a reference to each element preventing their reuse.
We can however can do much better. And that is by comparing the column to the sorted version of the column. If they do not match, then we can increment our counter.
class Solution:
def minDeletionSize(self, A: List[str]) -> int:
counter = 0
for col in zip(*A):
if list(col) != sorted(col):
counter += 1
return counter
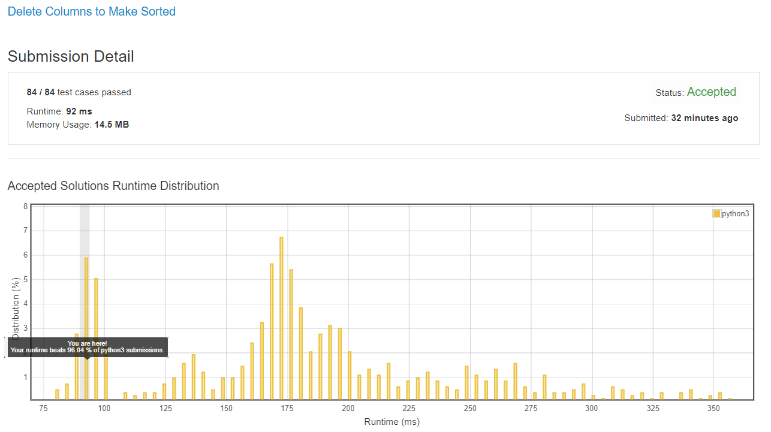
A runtime of 92ms, better then 96% of python3 submission! Why is this so much faster, since theoretically it has a worse runtime analysis? Since we are doing an inner sort for each column the runtime is O(MNLogN) where N is the size of a string and M is the size of A.
My theory as to why this works is due to the convenient constraint of 1 <= N <= 100. For a small enough N, O(N) does not have a significant performance gain over sorting O(NLogN). Since we are sorting in-line and doing the comparison in-line, we do not allocate any memory to the variables a and b as I do in my previous solution. And consequently, we see this significant boost.